Building large arabic multi-domain resources for sentiment analysis
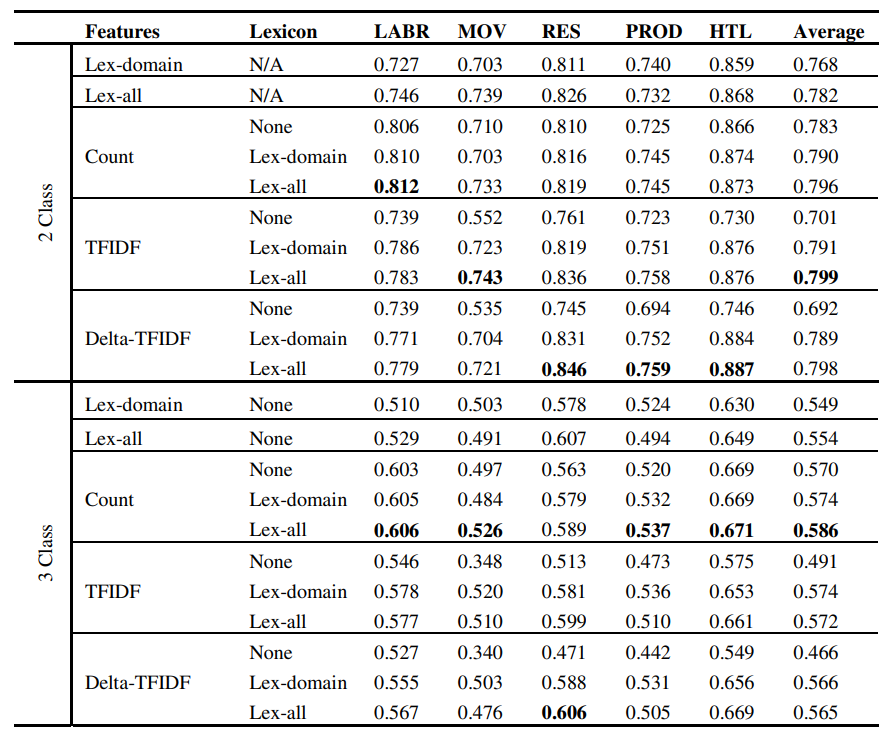
While there has been a recent progress in the area of Arabic SentimentAnalysis, most of the resources in this area are either of limited size, domainspecific or not publicly available. In this paper, we address this problemby generating large multi-domain datasets for Sentiment Analysis in Arabic.The datasets were scrapped from different reviewing websites and consist of atotal of 33K annotated reviews for movies, hotels, restaurants and products.Moreover we build multi-domain lexicons from the generated datasets. Differentexperiments have been carried out to validate the usefulness of the datasetsand the generated lexicons for the task of sentiment classification. From the experimentalresults, we highlight some useful insights addressing: the best performingclassifiers and feature representation methods, the effect of introducinglexicon based features and factors affecting the accuracy of sentiment classificationin general. All the datasets, experiments code and results have been madepublicly available for scientific purposes. © Springer International Publishing Switzerland 2015.