

Investigating analysis of speech content through text classification
The field of Text Mining has evolved over the past years to analyze textual resources. However, it can be used in several other applications. In this research, we are particularly interested in performing text mining techniques on audio materials after translating them into texts in order to detect the speakers' emotions. We describe our overall methodology and present our experimental results. In particular, we focus on the different features selection and classification methods used. Our results show interesting conclusions opening up new horizons in the field, and suggest an emergence of
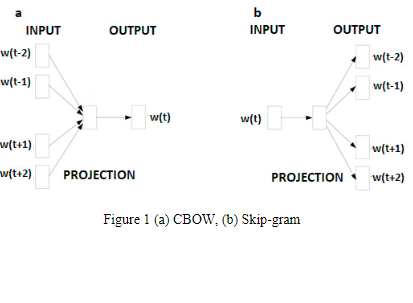
AraVec: A set of Arabic Word Embedding Models for use in Arabic NLP
Advancements in neural networks have led to developments in fields like computer vision, speech recognition and natural language processing (NLP). One of the most influential recent developments in NLP is the use of word embeddings, where words are represented as vectors in a continuous space, capturing many syntactic and semantic relations among them. AraVec is a pre-Trained distributed word representation (word embedding) open source project which aims to provide the Arabic NLP research community with free to use and powerful word embedding models. The first version of AraVec provides six
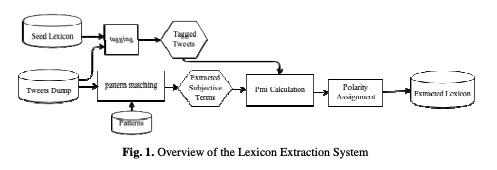
A fully automated approach for Arabic slang lexicon extraction from microblogs
With the rapid increase in the volume of Arabic opinionated posts on different social media forums, comes an increased demand for Arabic sentiment analysis tools and resources. Social media posts, especially those made by the younger generation, are usually written using colloquial Arabic and include a lot of slang, many of which evolves over time. While some work has been carried out to build modern standard Arabic sentiment lexicons, these need to be supplemented with dialectical terms and continuously updated with slang. This paper proposes a fully automated approach for building a
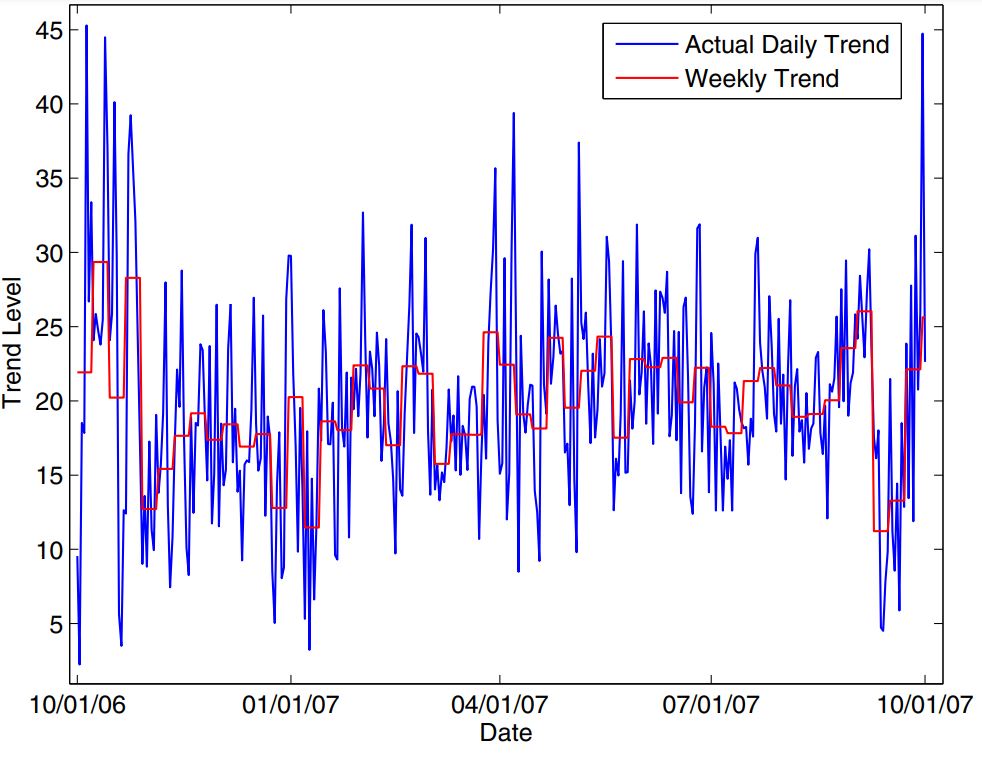
Exploiting neural networks to enhance trend forecasting for hotels reservations
Hotel revenue management is perceived as a managerial tool for room revenue maximization. A typical revenue management system contains two main components: Forecasting and Optimization. A forecasting component that gives accurate forecasts is a cornerstone in any revenue management system. It simply draws a good picture for the future demand. The output of the forecast component is then used for optimization and allocation in such a way that maximizes revenue. This shows how it is important to have a reliable and precise forecasting system. Neural Networks have been successful in forecasting
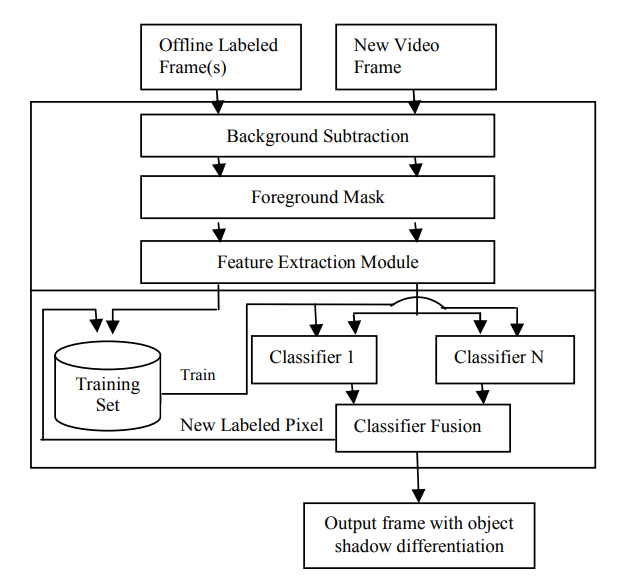
A semi supervised learning-based method for adaptive shadow detection
In vision-based systems, cast shadow detection is one of the key problems that must be alleviated in order to achieve robust segmentation of moving objects. Most methods for shadow detection require significant human input and they work in static settings. This paper proposes a novel approach for adaptive shadow detection by using semi-supervised learning which is a technique that has been widely utilized in various pattern recognition applications and exploits the use of labeled and unlabeled data to improve classification. The approach can be summarized as follows: First, we extract color
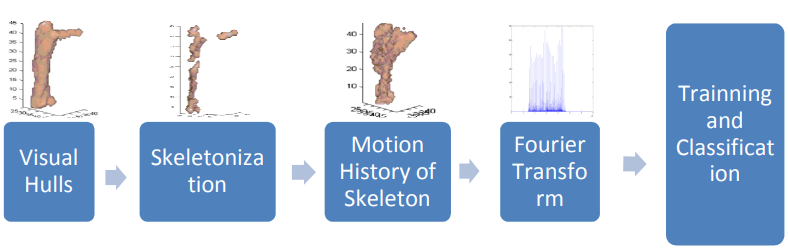
Motion history of skeletal volumes for human action recognition
Human action recognition is an important area of research in computer vision. Its applications include surveillance systems, patient monitoring, human-computer interaction, just to name a few. Numerous techniques have been developed to solve this problem in 2D and 3D spaces. However most of the existing techniques are view-dependent. In this paper we propose a novel view-independent action recognition algorithm based on the motion history of skeletons in 3D. First, we compute a skeleton for each volume and a motion history for each action. Then, alignment is performed using cylindrical
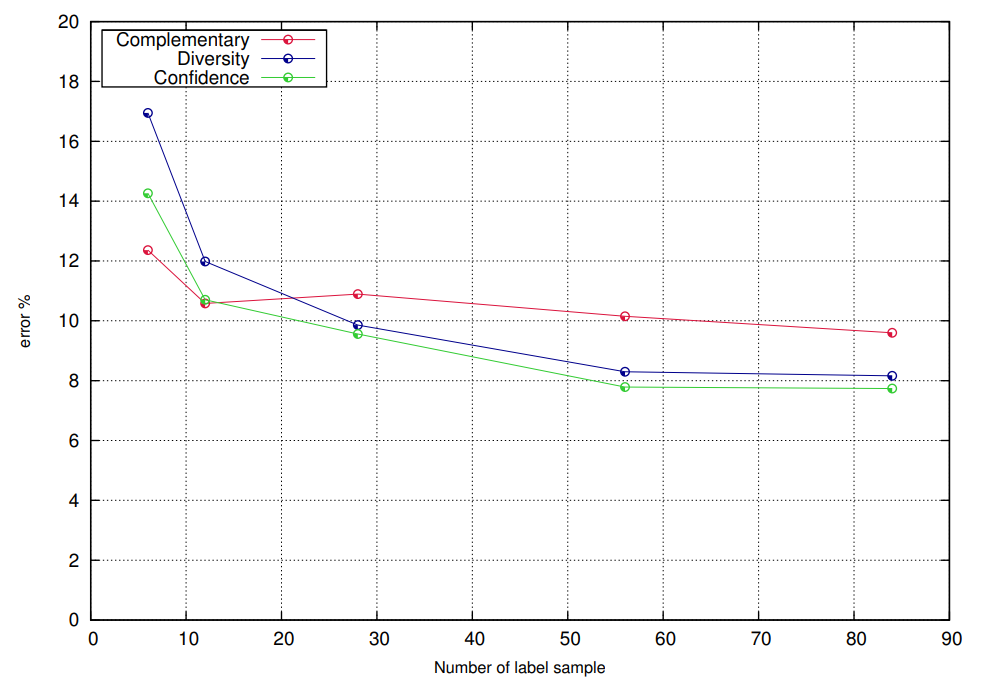
Complementary feature splits for co-training
In many data mining and machine learning applications, data may be easy to collect. However, labeling the data is often expensive, time consuming or difficult. Such applications give rise to semi-supervised learning techniques that combine the use of labelled and unlabelled data. Co-training is a popular semi-supervised learning algorithm that depends on splitting the features of a data set into two redundant and independent views. In many cases however such sets of features are not naturally present in the data or are unknown. In this paper we test feature splitting methods based on
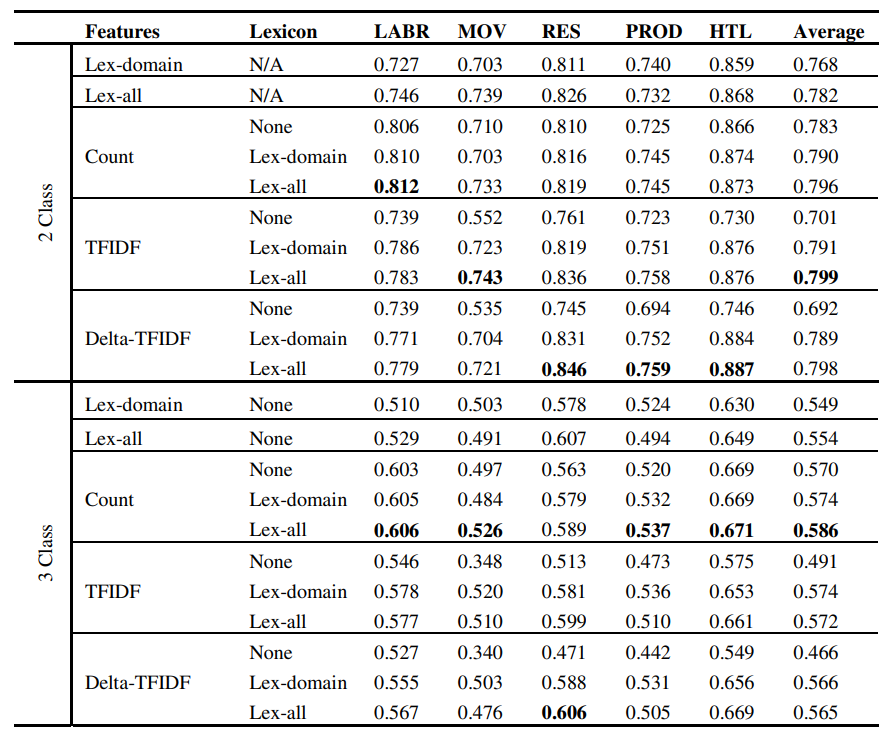
Building large arabic multi-domain resources for sentiment analysis
While there has been a recent progress in the area of Arabic SentimentAnalysis, most of the resources in this area are either of limited size, domainspecific or not publicly available. In this paper, we address this problemby generating large multi-domain datasets for Sentiment Analysis in Arabic.The datasets were scrapped from different reviewing websites and consist of atotal of 33K annotated reviews for movies, hotels, restaurants and products.Moreover we build multi-domain lexicons from the generated datasets. Differentexperiments have been carried out to validate the usefulness of the
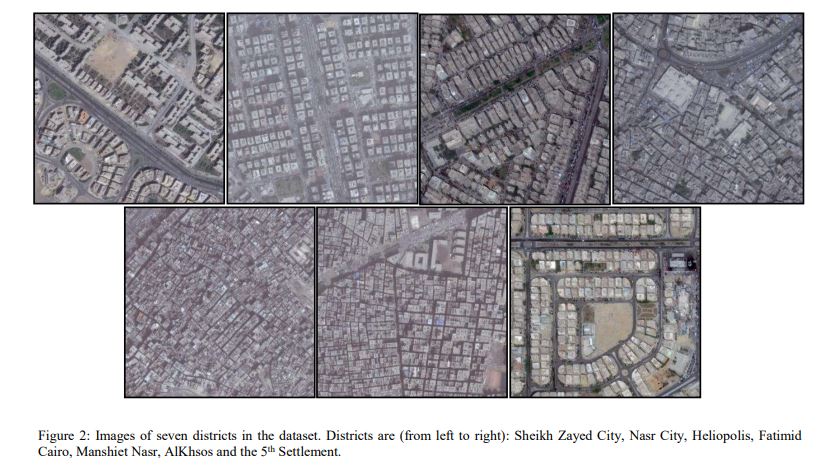
Convolutional Neural Network-Based Deep Urban Signatures with Application to Drone Localization
Most commercial Small Unmanned Aerial Vehicles (SUAVs) rely solely on Global Navigation Satellite Systems (GNSSs) - such as GPS and GLONASS - to perform localization tasks during the execution of autonomous navigation activities. Despite being fast and accurate, satellite-based navigation systems have typical vulnerabilities and pitfalls in urban settings that may prevent successful drone localization. This paper presents the novel concept of 'Deep Urban Signatures' where a deep convolutional neural network is used to compute a unique characterization for each urban area or district based on

Combining lexical features and a supervised learning approach for arabic sentiment analysis
The importance of building sentiment analysis tools for Arabic social media has been recognized during the past couple of years, especially with the rapid increase in the number of Arabic social media users. One of the main difficulties in tackling this problem is that text within social media is mostly colloquial, with many dialects being used within social media platforms. In this paper, we present a set of features that were integrated with a machine learning based sentiment analysis model and applied on Egyptian, Saudi, Levantine, and MSA Arabic social media datasets. Many of the proposed